在人工智能領域,大語言模型的迅猛發展正在改變著信息處理的格局。作為大模型應用的關鍵支撐技術,Embedding模型正成為業界的焦點。近日,人工智能及大數據科技企業合合信息發布了其自主研發的文本向量化模型——acge_text_embedding(簡稱“acge模型”),并在權威的中文文本向量評測基準C-MTEB中榮登榜首。
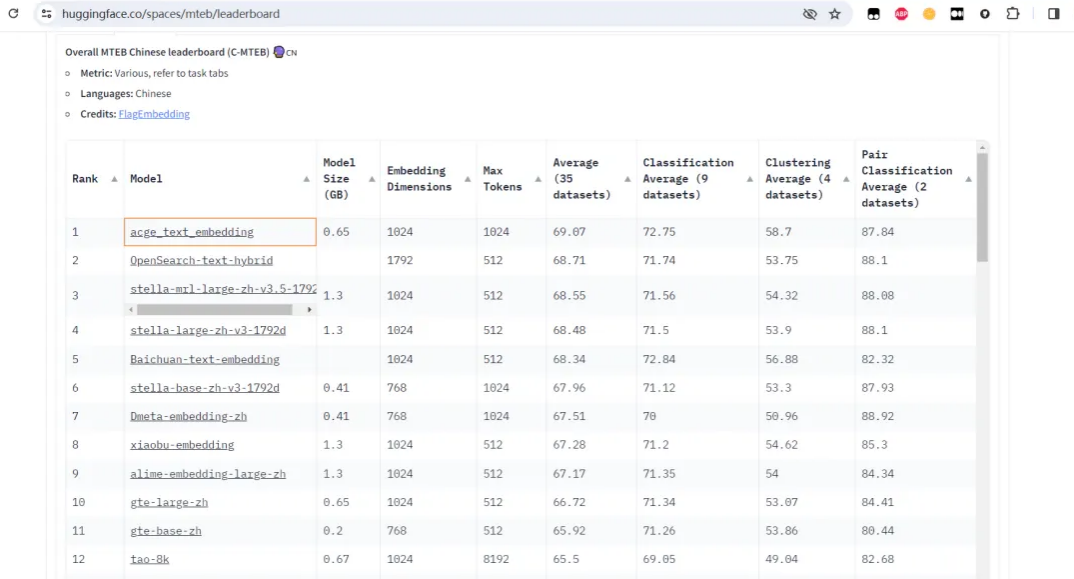
MTEB被公認為是目前業界最全面、最權威的中文語義向量評測基準之一,涵蓋了分類、聚類、檢索、排序、文本相似度、STS等6個經典任務,共計35個數據集,為深度測試中文語義向量的全面性和可靠性提供了可靠的實驗平臺。
Embedding模型的核心功能是將高維離散數據轉換為低維連續向量,從而捕捉數據的語義特征和關系。在互聯網時代,這一技術對于提升搜索、推薦、問答等應用的準確性和效率具有重要意義。acge模型的發布,不僅為這些應用提供了更強大的技術支持,也為大模型在實際落地應用過程中注入了新的活力。
據了解,合合信息的技術團隊在acge模型的開發過程中,對數據集和訓練策略進行了深入的優化。他們構造了大量的數據集,確保模型的訓練質量和場景覆蓋面;同時,引入了多種有效的模型調優技術,使得acge模型在不同場景下都能表現出色。
值得一提的是,acge模型在多個方面都展現出了明顯的優勢。相比于傳統的預訓練或微調垂直領域模型,acge模型不僅支持通用分類模型的構建,還能提升長文檔信息抽取的精度。此外,該模型的應用成本相對較低,使得大模型能夠在多個行業中快速創造價值,推動科技創新和產業升級。
在具體實踐上,合合信息團隊采用了策略學習訓練方式,顯著提升了模型在檢索、聚類、排序等任務上的性能;同時,引入持續學習訓練方式,克服了神經網絡存在的遺忘問題,使得模型訓練迭代能夠達到優秀的收斂空間。
未來,隨著大語言模型和Embedding技術的不斷進步,我們有理由相信,合合信息將繼續在人工智能領域取得更好的成績。
免責聲明:市場有風險,選擇需謹慎!此文僅供參考,不作買賣依據。
關鍵詞:








