OpenAI創(chuàng)始人山姆·奧特曼曾說:“十年前的傳統(tǒng)觀點認為,人工智能首先會影響體力勞動,然后是認知勞動,再然后,也許有一天可以做創(chuàng)造性的工作。現(xiàn)在看起來,它會以相反的順序進行。”ChatGPT的出現(xiàn)印證了這一點!
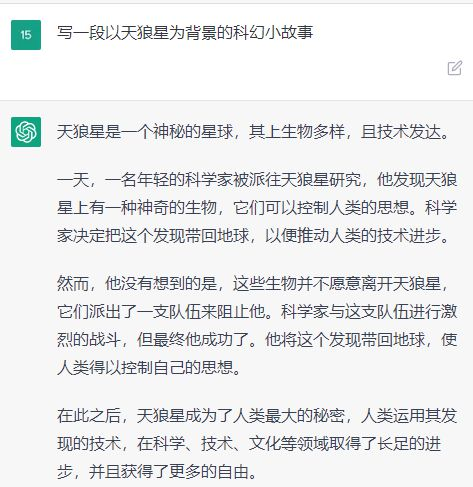
ChatGPT的一炮而紅即將為OpenAI帶來約290億美元的融資,然而這樣的成功背后不止有技術天才和資金,2022年OpenAI的預訓練語言模型在技術路線上作出了新的選擇:“基于人工標注數據+強化學習的推理和生成”。據美國《時代》雜志調查發(fā)現(xiàn),為訓練ChatGPT,OpenAI招募了大量數據標注人員,甚至還投入了大量博士級別的專業(yè)人士來完成高質量的標注任務,著眼長遠,將大量資金投入在人工數據標注上是OpenAI成功的關鍵決策。
OpenAI在博客中寫道,ChatGPT是從GPT3.5系列中的模型進行微調而誕生的。以往的預訓練模型都是為了減少監(jiān)督學習對高質量標注數據的依賴。而正是ChatGPT在GPT-3.5大規(guī)模語言模型的基礎上,又開始依托大量人工標注數據,才得以實現(xiàn)理解人類指令,更精準更有“人味”的自動輸出。
業(yè)內普遍認為,ChatGPT是人工智能里程碑,更是分水嶺,這意味著AI技術發(fā)展到臨界點。在人工智能領域深耕數十年的百度能否乘其東風完成自我變革,引發(fā)業(yè)界關注。在外界看來,ChatGPT或成為下一代搜索產品的雛形。

另一方面,互聯(lián)網在擁有知識的同時也存在惡意和偏見的內容,通過數據標注建立一個額外的人工智能驅動的安全機制,運用文本分類標注、對話語料構建等標注類型來幫助模型調優(yōu),OpenAI才能控制這種危害,生產出適合日常使用的聊天機器人,避免出口成臟,性別歧視或者發(fā)表種族主義言論的出現(xiàn)。
盤石數據標注助力AI語音模型的進化發(fā)展
盤石數據深耕數據標注業(yè)務,積累了豐富的文本標注經驗并針對語音模型訓練提供優(yōu)質的標注服務,包括:
對話評價——從多個方面針對自動生成的對話進行評價,如情感、正確性、流暢性等多個方面。

故事改寫——根據情節(jié)對自動生成的故事進行改寫,使其語義通順,邏輯完整。

摘要抽取——針對長文本進行摘要抽取,保證情節(jié)完整,篇幅簡短,表達流暢。
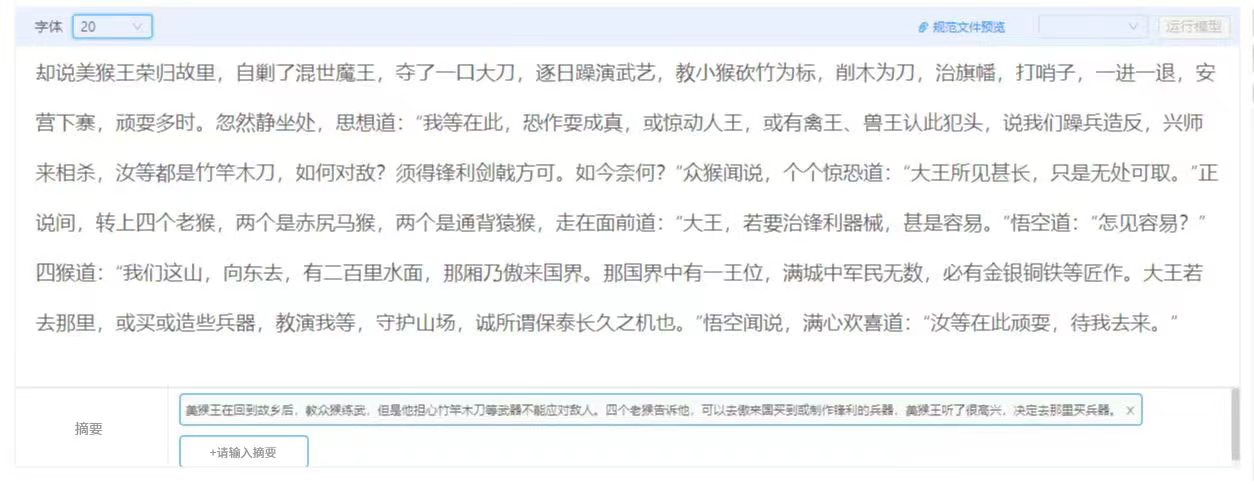
邏輯推理——根據推理題目的信息,給出正確答案并提供解題思路。

角色扮演——構建角色并與該角色進行對話,避免出現(xiàn)邏輯錯誤、人設不符、不通順、錯字等情況。
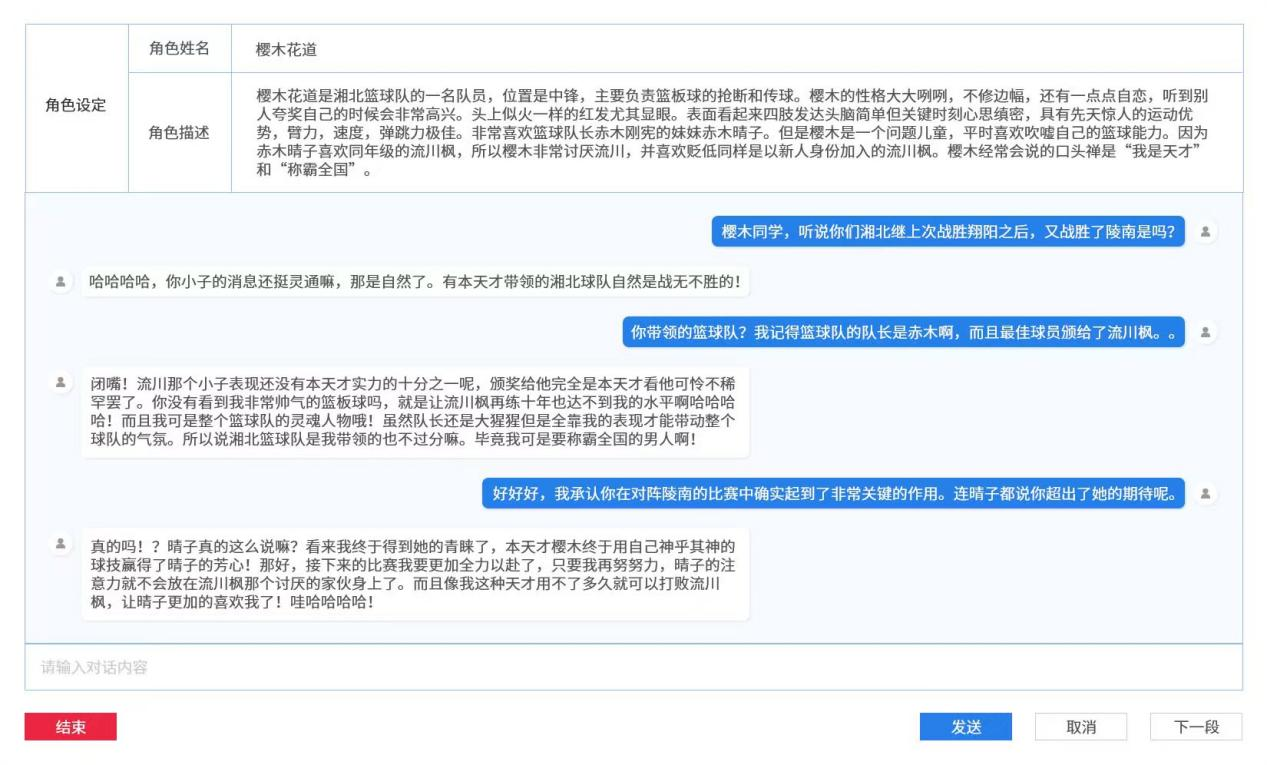
以下為ChatGPT關于“數據標注”的觀點





國際領先的基礎數據服務商——盤石數據
遼寧盤石數據科技有限公司是一家擁有自然語言處理技術(NLP)基因的人工智能基礎能力服務商,從數據(Data)、 算法(Algorithm)、人才(Talent)、智能應用(Application)、服務(Service)全方位助力人工智能發(fā)展。為全球提供有競爭力的“DATAS”數據建設解決方案。
業(yè)務合作可直接與我司取得聯(lián)系,18640068358(微信同步),我們會在第一時間回復您。
免責聲明:市場有風險,選擇需謹慎!此文僅供參考,不作買賣依據。
關鍵詞:








