12月7日,人工智能自然語言處理領(lǐng)域的頂級國際會議 EMNLP 2022 在阿布扎比開幕。EMNLP 聚焦于自然語言處理技術(shù)在各個應(yīng)用場景的學(xué)術(shù)研究,尤其重視自然語言處理的實證研究。該會議曾推動了預(yù)訓(xùn)練語言模型、文本挖掘、對話系統(tǒng)、機器翻譯等自然語言處理領(lǐng)域的核心創(chuàng)新,在學(xué)術(shù)和工業(yè)界都有巨大的影響力。此次會議上,由阿里云機器學(xué)習(xí)平臺 PAI 主導(dǎo)聯(lián)合阿里巴巴達摩院 NLP 團隊、華東師范大學(xué)高明教授團隊在小樣本學(xué)習(xí)方向的研究有3篇論文入選。
此次入選意味著阿里云機器學(xué)習(xí)平臺 PAI 自研的自然語言處理算法和框架達到了全球業(yè)界先進水平,獲得了國際學(xué)者的認可,展現(xiàn)了中國人工智能技術(shù)創(chuàng)新在國際上的競爭力。
小樣本學(xué)習(xí)論文簡述
預(yù)訓(xùn)練語言模型規(guī)模的擴大,帶來這一類模型在自然語言理解等相關(guān)任務(wù)效果的不斷提升。然而,這些模型的參數(shù)空間比較大,如果在下游任務(wù)上直接對這些模型進行微調(diào),為了達到較好的模型泛化性,需要較多的訓(xùn)練數(shù)據(jù)。小樣本學(xué)習(xí)技術(shù)能充分利用預(yù)訓(xùn)練過程中模型獲得的知識,在給定小訓(xùn)練集上訓(xùn)練得到精度較高的模型。本次阿里云機器學(xué)習(xí)平臺 PAI 共有 3 篇小樣本學(xué)習(xí)相關(guān)論文入選,簡述如下。
基于 Prompt-Tuning 的小樣本機器閱讀理解算法 KECP
傳統(tǒng)的機器閱讀理解任務(wù)通常需要大量的標注數(shù)據(jù)來微調(diào)模型(例如 BERT),這一任務(wù)通常需要采用序列標注或指針網(wǎng)絡(luò)的方法,獲得答案在給定文章的區(qū)間。然而,這種方法需要重頭開始學(xué)習(xí) Preduction Head 的參數(shù),在小樣本場景下容易過擬合。最近 Prompt-Tuning 相關(guān)方法的提出緩解了預(yù)訓(xùn)練語言模型在低資源場景下的過擬合問題。受到這個啟發(fā),我們將抽取式閱讀理解轉(zhuǎn)換為基于 BERT 的生成任務(wù)。我們提出的 KECP(Knowledge Enhanced Contrastive Prompt-tuning)模型綜合利用了模型表示的知識增強和對比學(xué)習(xí)技術(shù),提升了小樣本學(xué)習(xí)場景下的機器閱讀理解準確度,模型架構(gòu)如下圖。實驗結(jié)果可以證明,KECP 在一些常用的機器閱讀理解數(shù)據(jù)集上,在只有 16 個標注的訓(xùn)練樣本情況下,取得了比先前提出的模型更好的精度。
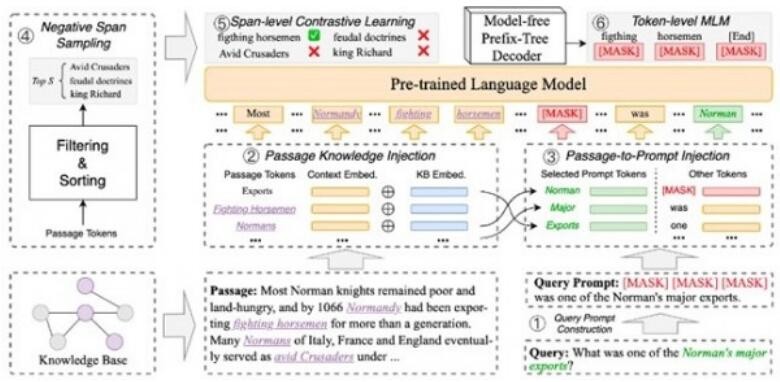
基于 Span 和元學(xué)習(xí)的小樣本實體識別算法 SpanProto
命名實體識別是 NLP 領(lǐng)域中非常常見的任務(wù),對于這一任務(wù),預(yù)訓(xùn)練語言模型的 Fine-tune 需要一定數(shù)量的語料來學(xué)習(xí) Token 與 Label(例如人名、地名)之間的依賴關(guān)系。但是在實際應(yīng)用中,標注數(shù)據(jù)資源比較稀缺,傳統(tǒng)的序列標注方法很難達到較好的效果,因為其需要解決實體識別中的標簽依賴(Label Depnedency)關(guān)系,同時也無法應(yīng)對實體嵌套(Nested Entity)問題。因此,我們研究一種基于 Span 和元學(xué)習(xí)的小樣本實體識別技術(shù) SpanProto,特別地,我們關(guān)注于解決 N-way K-shot 的實體識別場景。SpanProto 采用兩階段方法,即將實體識別任務(wù)分解為兩個階段,分別是 Span Extraction 和 Mention Classification,模型框架圖如下所示。
在 Span Extraction 模塊中,SpanProto 使用與類別無關(guān)的 Span 抽取器,抽取出可能的命名區(qū)間。在 Mention Classification 模塊中,SpanProto 采用 Prototypical Learning 給每個 Span 分配標簽;與此同時,我們考慮到命名實體識別的 False Positive 問題,即存在一些抽取的 Span 在當前 Episode 內(nèi)沒有合適的類別可以分配的情況。為了驗證 SpanProto 算法的有效性,我們在 Few-NERD 這一標準評測數(shù)據(jù)集上進行了測試,效果證明 SpanProto 對精度提升明顯。
統(tǒng)一跨任務(wù)小樣本學(xué)習(xí)算法 UPT
基于提示微調(diào)(Prompt Tuning)的小樣本學(xué)習(xí)技術(shù)能充分利用預(yù)訓(xùn)練過程中模型獲得的知識,在給定小訓(xùn)練集上訓(xùn)練得到精度較高的模型。然而,在小樣本學(xué)習(xí)場景下,訓(xùn)練數(shù)據(jù)的有限性仍然對模型的準確度造成一定的制約。因此,如果可以在小樣本學(xué)習(xí)階段,有效利用其它跨任務(wù)的數(shù)據(jù)集,可以進一步提升模型的精度。跨任務(wù)小樣本學(xué)習(xí)算法 UPT(Unified Prompt Tuning)是一種統(tǒng)一的學(xué)習(xí)范式,可以將各種下游任務(wù)和預(yù)訓(xùn)練任務(wù)統(tǒng)一成 POV(Prompt-Options-Verbalizer)的形式,使得模型可以學(xué)習(xí)利用Prompt 解決各種 NLP 任務(wù),UPT 的任務(wù)構(gòu)造形式如下所示。

無論是單句分類任務(wù),還有雙句匹配任務(wù),亦或是預(yù)訓(xùn)練階段的自監(jiān)督學(xué)習(xí)任務(wù),UPT 可以將他們轉(zhuǎn)化成一種統(tǒng)一的范式進行學(xué)習(xí)。這種學(xué)習(xí)方式兼顧了經(jīng)典的小樣本學(xué)習(xí)算法的優(yōu)勢,又在學(xué)習(xí)過程中引入了“元學(xué)習(xí)”(Meta Learning)的思想,大大提升了模型對下游任務(wù)的泛化性,緩解了其在小樣本學(xué)習(xí)階段遇到的過擬合問題。當我們訓(xùn)練得到這一 Meta Learner 之后,我們可以復(fù)用先前的算法,對 Meta Learner 進行 Few-shot Fine-tuning。我們在多個 GLUE 和 SuperGLUE 數(shù)據(jù)集上驗證了 UPT 的實驗效果,實驗結(jié)果表明,我們提出的自研算法 UPT 具有明顯精度提升。
EasyNLP 算法框架及算法應(yīng)用
為了更好地服務(wù)開源社區(qū),上述三個算法的源代碼即將貢獻在自然語言處理算法框架 EasyNLP 中,歡迎 NLP 從業(yè)人員和研究者使用。EasyNLP 是阿里云機器學(xué)習(xí) PAI 團隊基于 PyTorch 開發(fā)的易用且豐富的中文 NLP 算法框架,支持常用的中文預(yù)訓(xùn)練模型和大模型落地技術(shù),并且提供了從訓(xùn)練到部署的一站式 NLP 開發(fā)體驗。由于跨模態(tài)理解需求的不斷增加,EasyNLP 也將支持各種跨模態(tài)模型,特別是中文領(lǐng)域的跨模態(tài)模型,推向開源社區(qū),希望能夠服務(wù)更多的 NLP 和多模態(tài)算法開發(fā)者和研究者,也希望和社區(qū)一起推動 NLP/多模態(tài)技術(shù)的發(fā)展和模型落地。機器學(xué)習(xí)平臺 PAI 面向企業(yè)客戶級開發(fā)者,提供輕量化、高性價比的云原生機器學(xué)習(xí),涵蓋 PAI-DSW 交互式建模、PAI-Designer 可視化建模、PAI-DLC 分布式訓(xùn)練到 PAI-EAS 模型在線部署的全流程。
Github地址:https://github.com/alibaba/EasyNLP
阿里云機器學(xué)習(xí)平臺PAI論文入選 EMNLP 2022 列表
1. KECP: Knowledge-Enhanced Contrastive Prompting for Few-shot Extractive Question Answering
論文作者:王嘉寧、汪誠愚、譚傳奇、邱明輝、黃松芳、黃俊、高明
2.SpanProto: A Two-stage Span-based Prototypical Network For Few-shot Named Entity Recognition
論文作者:王嘉寧、汪誠愚、邱明輝、石秋慧、王洪彬、黃俊、高明
3.Towards Unified Prompt Tuning for Few-shot Text Classification
論文作者:王嘉寧、汪誠愚、羅福莉、譚傳奇、邱明輝、楊非、石秋慧、黃松芳、高明
免責聲明:市場有風(fēng)險,選擇需謹慎!此文僅供參考,不作買賣依據(jù)。
關(guān)鍵詞: